
A business relies on data stored in multiple places. Managing it to provide positive customer and employee experiences takes a lot of work.
Let’s illustrate how it is difficult without data fabric and the Power of Data Fabric for Enterprise Success:
A major insurance company customer files a claim after some property damage. The customer will be anxious for that claim to be processed quickly. So, the customer will call the insurance company and talk to the claim representative, who is good at their job.
Analyzing a claim is not for the faint of heart. Each share can generate massive amounts of unstructured data such as text, videos, photos, audio files, etc. The representative needs a secure and unified view of the customer’s data and insurance details to process the claim quickly. In other words, They need access to the right data at the right time regardless of where it happens to live.
But the insurance company stores its data across multiple silos, which can unintentionally make accessing, using, and analyzing that data much more complicated for the representative.
As a customer, the enterprise’s data may be fragmented across warehouses, data lakes, and multiple clouds. They might be asking why not store the customer’s data together in one place.
But that could create a never-ending ripple effect of compliance, governance, and security problems.
Luckily, here is another solution in the form of a data fabric.
What is Data Fabric?
Data fabric I like a tapestry that connects data across silos, be it on-premises or across multiple clouds, without ever having to copy or move any data. It also helps an organization maintain its level of governance and privacy.
A data fabric allows organizations to make information quickly available across a network that connects the right data to the right people at the right time.

Benefits of Data Fabric for Enterprise Success
- Easier data management, security, reliability, and consistency.
- Well-documented metadata makes the overall environment simpler to maintain.
- Democratization of data and analytical assets.
- Easy discovery and navigation of all the data assets by all users from a centralized data access mechanism.
- Reduction of complexity
Promoting automation and streamlining processes that create and maintain the environment.
- A coordinated, documented process of data lineage and usage.
- Information about where data came from, what happened to it on its journey, the analytical assets that use it, and who uses that data and assets makes for a better-managed environment.
- Data redundancy, inaccuracy, senescence, and potential security/privacy breaches can be better controlled here than in a chaotic, undocumented situation.
- A controlled environment promotes better governance as well.
Data Fabric for Enterprises Success
Use Case: Operational Analytic
| Embedded or callable BI services | Real-time Analysis Engine |
| Real-time fraud detection | Traffic flow optimization |
| Real-time loan risk assessment | Web event analysis |
| Optimizing online promotions | Natural resource exploration analysis |
| Location-based offers | Stock trading analysis |
| Contact center optimization | Risk analysis |
| Supply chain optimization | Correlation of unrelated data streams (e.g., weather effects on product sales) |

Data Provisioning Use Case: Data Integration
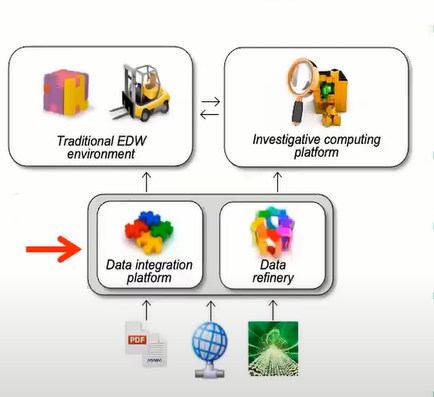
- Heavy lifting process of extracting, transforming to a standard format, and loading structured data.
- Physically consolidate data into “trusted” EDW sets for analysis.
- Invokes data quality processing where needed.
- Employs low-cost hardware and software to enable large data volumes to be continued and stored.
- Requires more formal governance policies to manage data security, privacy, quality, archiving, and destruction.
- Ingest raw, detailed structured, and unstructured data in batch and real-time into a managed data store.
- Disnills data into useful business information and distributes the results to downstream systems.
- It may also directly analyze certain types of data.
- It also employs low-cost hardware and software to manage large amounts of detailed data cost-effectively.
- Requires (flexible) governance policies to manage data security, privacy, quality, archiving, and destruction.
Use Case: Traditional EDW

Most BI environments today:
- Can incorporate new technologies into the EDW environment to improve performance and efficiency and reduce costs.
Use Case:
- Production reporting
- Historical Comparisons
- Customer analysis (next best offer, segmentation, lifetime value score, etc.)
- KPI calculations
- Profitability analysis
- Forecasting
Use Case: Investigative Computing

New technologies, including
- Hadoop, in-memory computing, columnar storage, data compression, application, etc.
Use Case:
- Data mining and predictive modeling for EDW, and real-time environments.
- Cause and effect analysis.
- Data exploration (“Did this ever happen?”, “How often?”)
- Pattern analysis
- Genera, unplanned investigations of data.
Use Case: Analytic Tools and Applications

The variety of technologies that:
- Create the reports.
- Perform the analysis
- Perform the analyses
- Display the results and increase the productivity of
analysis and data scientists.
Other Sources of Data

Other internal or external data:
- Source of data that are not in the normal streams for this architecture, like purchased structured data.
- Includes streaming data such as IoT data and social media data.
Data Flow in the Extended Analytic Architecture (XAA)
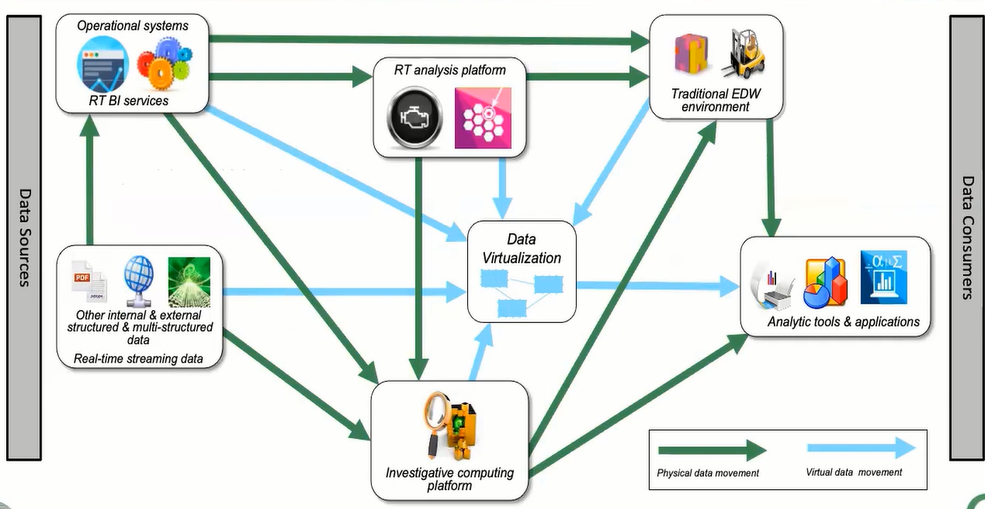
Implementing the Data Fabric – Technological Support
Data Catalog: A “storefront” containing all technical metadata, a business glossary, a data dictionary, and governance attributes:
- This information is generated by other technologies, like data modeling, integration, or data prep tools, but it is consolidated here and resented to users via the catalog interface.
- Data catalogues can perform certain analyses like
- Data lineage
- Impact analysis.
They can determine sensitive data and present recommendations to business users.
Data Modeling
Each repository in the architecture must have its schema documented through a data modeling technology:
- The different levels of data models (logical and physical) used in designing the EDW and ICP.
- Data models of operating systems are used in data integration and prep technologies.
- Data molding technology is also a key supplier of the information found in the data catalog, including any changes to database design, the existence of data, its location, definitions, and other glossary items.
- Data models must be connected to the business glossary to ensure a well. Managed data catalog.
Integration of Data
A key factor in creating the EDW:
- Data integration technologies (ETL, or ELT) extract the data from different sources and transform it into trusted data that is then loaded into the EDW.
- A best practice is to automate as much of this process as an enterprise can transform from creation to design and deployment.
- Documentation is a mandatory by-product of this process.
Data Preparation
The creation of the data lake or ICP is supported by data prep technology:
- Data prep technology extracts raw data from sources, reformats, highly integrates it, and loads it into the repository for exploration or experimentation.
- The ICP is meant for unplanned, general queries data scientists perform.
- Again, the data pep tools should automate this process and produce the much-needed documentation.
Data Virtualization
The ability to bring data together virtually rather than physically moving it around the architecture:
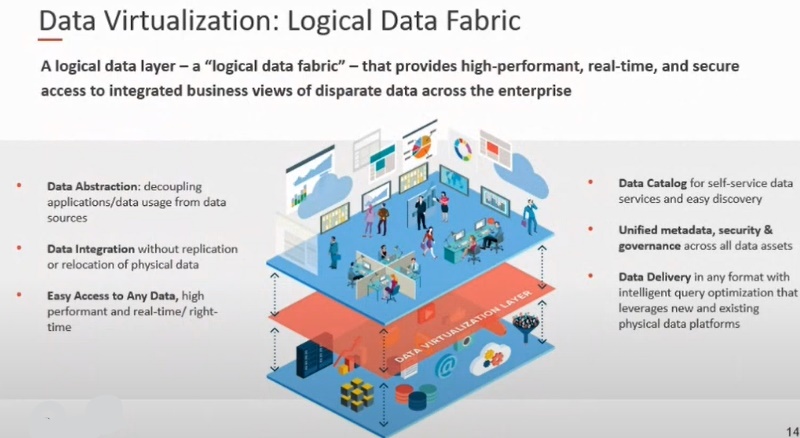
- Access to all data, regardless of location, is a major step toward democratization,
- To aid performance, it can cache popular virtualized data in memory.
- Can also use virtualization for prototyping new solutions or environmental additions.
Analysis and Visualization of Data
The world of data analysis and visualization technologies is massive:
- The analytical capabilities range from simple reporting and dashboard creation to complex and artistic data visualizations to predictive and other advanced analyses.
- No single technology in this category can satisfy all business community needs. So, multiple tools will likely be needed, at least one in each category.
Monitoring
Many usage statistics in the data catalog originate from monitoring technologies used in the EDW and ICP.
- The ability to monitor what data is being used and by whom gives the technical personnel great insight into the overall performance of these analytical repositories.
- As an example, data rarely used may be stored in archive media, seasonal or other time-based spikes in utilization can be planned for, and may cache commonly used data together or virtually brought together for better performance.
Suitable data Storage
Rounding out the data fabric store and then analyzing the environment are the various data storage technologies – the database themselves.
- In the past, we had to separate the data warehouse from the investigative area because the analytical techniques used for both were incompatible.
- With the separation of data storage from computing, we now see situations where the data warehouse and ICP can reside in the same storage technology.
Real-time Analytic Engine
The last area of analysis deals with analyzing data streaming into the organization:
- A major difference from the EDW or ICP is the data is analyzed before it is stored.
- This technology must bring together multiple data streams that are analyzed in a real-time mood.
- It is a relatively new area of analytics but is a welcomed addition to the family of analytical components in the data fabric
Author: Huma Tariq
Copyright The Cloudflare.

